LEAN file system specification 0.6
Version 0.6.0, last update: 2010-03-10
Copyright © 2004-2010 by Salvatore ISAJA (the Author)
Permission to make and distribute verbatim copies of this specification, translations of this specification into another language, and derivative works that comment on or otherwise explain it or assist in its implementation, for any purpose and without fee or royalty is hereby granted, provided that the present copyright notice, licensing terms and disclaimer are preserved on all copies.
In addition, the Author covenants not to assert any claims on implementations of this specification, unless such implementations contain derivative work of implementations by the Author, for which specific licensing terms may apply.
THIS SPECIFICATION IS PROVIDED "AS IS," AND THE AUTHOR MAKES NO REPRESENTATIONS OR WARRANTIES, EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, NON-INFRINGEMENT, OR TITLE; THAT THE CONTENTS OF THIS SPECIFICATION ARE SUITABLE FOR ANY PURPOSE; NOR THAT THE IMPLEMENTATION OF SUCH CONTENTS WILL NOT INFRINGE ANY THIRD PARTY PATENTS, COPYRIGHTS, TRADEMARKS OR OTHER RIGHTS. TO THE FULLEST EXTENT PERMITTED BY APPLICABLE LAW, THE AUTHOR WILL NOT BE LIABLE FOR ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF ANY USE OF THIS SPECIFICATION OR THE PERFORMANCE OR IMPLEMENTATION OF THE CONTENTS THEREOF.
No other rights are granted by implication, estoppel or otherwise.
This document describes version 0.6 of the LEAN file system (where the word LEAN is a recursive backronym for Lean yet Effective Allocation and Naming, based on the ironical contrary of FAT, as an English word): a free, simple, portable, personal, fully featured file system for embedded tasks. Minor changes made to this document (e.g. wording) that do not affect the file system format are tracked by the third number in the document version number.
The LEAN file system is in the alpha (unstable) development stage: this document supersedes any previous version of the LEAN file system specification with no care for backward compatibility.
Since this is a new file system, and some aspects are still to be defined, suggestions or corrections are welcome, for either the file system or this document. Please contact the author sending e-mail at: salvois at users.sourceforge.net. The author wishes to thank those who have submitted comments and criticism in order to improve the LEAN file system.
Table of contents
- Differences from the previous versions and future plans
- Definitions
- Partition identifier
- Structure identification and checksum
- Bands
- The superblock
- The bitmap
- The data area and file allocation
- The inode structure
- Directories
- Symbolic links
- Extended attributes
Differences from the previous versions and future plans
- version 0.6
- License: the GNU Free Documentation License has been replaced with a custom license that makes more sense for a specification.
- Preallocation: added support for drivers that may want to preallocate more disk space than needed for a file to reduce fragmentation and improve locality.
- Creation time stamp: creation and last status modification time stamps have been splitted.
- Extended attribute names: introduced constrains on names of extended attributes for compatibility with existing extended attribute APIs.
- Inline extended attributes: there are only two options for inline extended attributes now: do not use them, or reserve the whole space after the inode structure in the first sector, instead of the old
inodeExtraparameter. - Naming convention: removed identifiers in
ALL_CAPITALSto avoid clash with the conventional namespace of C and C++ macros.
- version 0.5
- Directory entry restrictions: directory entries are no longer required to fit within a single sector. This increases the maximum file name length, and makes storage of directory entries and extended attributes consistent.
- version 0.4
- File allocation: new definitions for some fields of the inode structure to simplify traversal of indirect sectors.
- Extended attributes: extended attributes can now be stored in an optional extra space after the inode structure, or in a separate fork for each file.
- Access control: POSIX permissions, although optional, have been included. Access Control Lists may be added in a future version using an extended attribute.
- version 0.3
- Sector size: sector size is now fixed to 512 bytes. This simplifies the layout of several structures and implementation of drivers. A driver should convert actual disk sectors to conventional sectors in case they differ.
- 64-bit addressing: sector addressing has been extended from 32-bit to 64-bit. Extent sizes are still 32-bit to reduce bookkeeping space. The layout of all data structures has been modified to accomodate the new sizes.
- version 0.2
- Multiband layout: a volume is split in bands, each with its portion of the bitmap.
- Extent-based allocation: file allocation is expressed in terms of extents instead of the old clusters.
- File name restrictions: removed constrains on characters not allowed in file names.
Definitions
The following terms and conventions will be used throughout this specification:
- must, must not, should, should not, may: these words are to be interpreted as described in RFC 2119;
- reserved for future use: a data field that has not yet been defined. When creating a new entry that field must be written as zeros. When reading an existing entry, a driver must not make assumption about the content of that field. When writing that field to an existing entry, a driver must preserve the value in that field;
- byte: a group of eight adjacent bits, an octet;
- driver: a file system driver, or any other part of the operating system, or any application implementing this specification to access a LEAN file system;
- disk: a block device hosting a LEAN file system. This wording is used for simplicity, although that device does not need to be an actual disk memory (e.g. disk partition, memory card, RAM disk). Drivers must limit disk sizes to 263-1 sectors, that is the maximum number that can be represented with a signed 64-bit integer;
- sector: a conventional block of 512 bytes. The disk must be an array of contiguous sectors, numbered starting from zero. LEAN conventional sectors may differ from actual disk sectors in size;
- volume: a self contained LEAN file system on a disk;
- superblock: a structure containing fundamental information about a volume;
- bitmap: a structure tracking free sectors of a volume;
- band: a portion of the disk made up of several contiguous sectors. Each band stores a part of the bitmap, in order to take advantage of locality in space;
- data area: part of a volume storing files, directories and other file system objects;
- directory: a special file storing a list of directory entries;
- directory entry: a structure containing a file name and location;
- inode structure: a structure containing fundamental information about a file. The inode structure of a file is stored in the first sector of the file;
- inode number: the sector number of the first sector of a file, that is the sector containing the inode structure of the file. The inode number must uniquely identify a file on a volume;
- extent: a contiguous addressable portion of a file, specified by a starting sector and a size;
- fork: a special file, associated with another non-fork file, storing a list of extended attributes;
- extended attribute: a structure containing an arbitrary name-value pair of metadata;
- The C++ syntax is used for code snippets and structure formats, with stdint.h integral types. The
chartype is assumed to be 8-bit. Hex numbers are prefixed with0x; - Unless otherwise stated, all numbers must be stored in little endian format (least significant byte first).
Partition identifier
On the i386 platform, each file system is identified by an 8-bit number in an entry of an MBR partition table. The value 0xEA (after LEAN) has been proposed as it seems unassigned.
For GUID partition tables the following GUID is provided to identify a LEAN data partition:
bb5a91b0-977e-11db-b606-0800200c9a66
Structure identification and checksum
Several structures of LEAN include fields to make the file system more robust.
Sensitive structures store a checksum field in their first 32 bits. The checksum is computed on any data following the checksum field itself, up to the end of the sensitive structure. The sensitive structure must be cast to an array of 32-bit unsigned integers, then each element of this array must be summed, rotating the sum one bit to right at every iteration. The size of the sensitive structure must be a multiple of 4 bytes. The checksum must be recomputed at least every time a sensitive structure is written back to disk.
The following function shows how to calculate the checksum. The data parameter is a pointer to the sensitive structure, including the checksum field in its first 4 bytes. The size parameter is the size in bytes of the structure pointed by data, including the 4 bytes for the checksum field. It must be a multiple of 4 bytes. The function skips the first 4 bytes when computing the checksum.
uint32_t computeChecksum(const void* data, size_t size) { uint32_t res = 0; const uint32_t* d = static_cast<const uint32_t*>(data); assert((size & (sizeof(uint32_t) - 1)) == 0); size /= sizeof(uint32_t); for (size_t i = 1; i != size; ++i) res = (res << 31) + (res >> 1) + d[i]; return res; }
A sensitive structure also contains a magic field storing a 32-bit constant signature identifying the structure. This can be used as a first test to validate a sensitive structure.
A field specifying the address of the sector storing the structure itself is sometimes provided. This is another robustness measure against repair utilities, in case they are scanning a disk for sensitive data structure, and an image file containing a LEAN file system is stored on that disk.
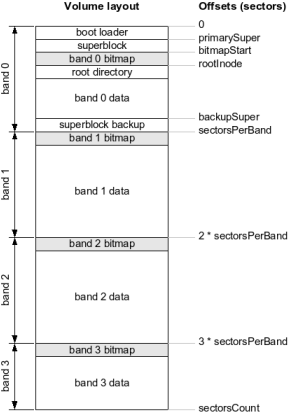
Figure 1: Layout of a LEAN volume.
Bands
To improve locality in space and to help dinamically change the size of a volume, the disk is logically subdivided into bands, made up of several contiguous sectors. Bands are equally sized, perhaps except the last one, and must be made up of a power of two worth of sectors. A volume contains at least one band. Bands are numbered starting from 0, where sector 0 is the first sector of band 0.
Each band contains a portion of the bitmap representing the allocation state of the sectors of that band. That is, each bitmap portion represents the state of closely located sectors. The bitmap portion for each band must start at the first sector of the band. Band 0 is an exception in that it contains sectors reserved for the boot loader and the superblock, thus a specific field is used to tell where the bitmap of band 0 starts.
The superblock
The superblock is a structure containing fundamental information about a LEAN volume. Its name comes from the ext2 file system, and it is used to differentiate it from the boot sector, that on i386 is sector 0, containing the code of the boot loader.
A driver must use the superblock to know how to access every other information on the volume. Thus, the superblock must be stored in a well known location. The superblock must be stored in one of any sector in range from 1 to 32, inclusive. This range should allow to scan for a superblock taking advantage of track buffering from the disk driver, while being flexible enough to overcome the limits of a fixed location. This leaves up to 16 KiB for the boot loader. A driver must use the magic, checksum and primarySuper fields of the superblock to identify a valid superblock.
A copy of the superblock must be present in a different location for backup purposes. A driver must ensure that the content of the backup copy is always exactly the same as the superblock. The location of the superblock backup is stored in the superblock to allow a driver update the backup copy. The backup copy of the superblock should be placed in the last sector of the first band, in order to help drivers locate it in the event the primary copy gets lost or corrupted (being band sizes constrained to powers of two). The magic, checksum and backupSuper fields must be used in this case.
Sectors before the superblock are reserved for a boot loader, they must not be used by a LEAN driver, and their content is undefined. The superblock may be shifted forward, up to the limit specified above, if more sectors are needed to store a boot loader. Sector 0 is always reserved.
In the FAT file system the boot sector embeds, besides the boot loader, volume status information. Thus, if a boot sector containing apparently valid FAT information is used on a LEAN volume, FAT drivers may erroneously detect the volume as FAT. Implementors and/or users may remove FAT related information from the boot sector (for example, zeroing every byte but the actual boot code), or try FAT detection at the end of the autodetection process. The LEAN design avoids storage of volume information in the boot sector for several reasons: platform independence, to use a compact, free format, where the fields are properly aligned and ordered, for robustness against a damaged sector 0, and to make room for boot loader code.
The format of the superblock is the following:
uint32_t checksum | The checksum value for the superblock. |
uint32_t magic | This must be equal to 0x4E41454C (the 'LEAN' characters in ASCII), and it must be used to identify a valid LEAN file system. It should be used to find the superblock backup in case the primary copy gets lost or damaged. |
uint16_t fsVersion | This field identifies the version of the LEAN file system, and it is provided for future development. The high byte identifies the major version number and the low byte the minor version number (for example 0x0110 would mean version 1.16). At present, in the alpha development stage, it must be set to 0x0006 (that is version 0.6) and drivers must not try to access an unknown file system version, backward compatibility making no sense. |
uint8_t preallocCount | The count minus one of contiguous sectors that the driver should try to preallocate when a new sector is to be added to a file. A value of zero means that the driver should append a single sector. Values greater than zero are recommended, especially for slowly-growing files such as directories, to reduce fragmentation and improve locality. |
uint8_t logSectorsPerBand | The base-2 logarithm of the number of sectors per band. The latter is easily computed as 1 << logSectorsPerBand. It must be at least equal to 12 (4096 bits per band, that is 512 bytes of a sector), so that a bitmap portion is always made up of an integral amount of sectors. This means that the smallest band size is 4096 sectors, that is 2 MiB. |
uint32_t state | This field identifies the state of the file system. Bit 0 (the LSB) is the clean unmount bit: it must be set to '0' while the volume is mounted, and it must set '1' while the volume is unmounted. Thus, if driver finds this bit set to '0' when mounting a volume, it means the volume was not unmounted properly. Bit 1 is the error bit: it must be normally '0'. Drivers must set it to '1' in case of major errors, like when file system corruption is detected. File system checkup programs may use this bit to know if some major problem happened with the volume. Bits 2 to 31 are reserved for future use. |
uint8_t uuid[16] | A 128-bit universally unique identifier (UUID) that should uniquely identify the volume. A driver should use it to check for media change in a removable media drive. A driver may use it for automatic volume identification. Drivers must create a sequence of 16 bytes as unique as possible, for example using a good random number generator or one of the canonical algorithms for UUID generation. |
char volumeLabel[64] | A descriptive string, encoded in Unicode UTF-8, null-terminated, to help the user identify the volume. It may be empty. |
uint64_t sectorCount | The total number of sectors that form the volume. |
uint64_t freeSectorCount | The number of free (or available, or unallocated) sectors in the volume. A driver must keep it consistent to the rest of the file system to measure the free volume space to store files, directories and book keeping. A value of zero must mean disk full. |
uint64_t primarySuper | The address of the sector containing the primary copy of the superblock. A driver must use this number to know where to write changes made to the superblock back to disk. This field is provided for robustness, for example against repair utilities operating on a disk containing a LEAN file system image file. |
uint64_t backupSuper | The address of the sector containing the backup copy of the superblock. A driver must use this number to know where to write the backup copy when changes are made to the superblock. In the event the primary copy of the superblock gets lost or damaged, recovery utilities should search for the backup copy of the superblock looking for valid magic and checksum fields, and may also use the backupSuper field itself for further validation. |
uint64_t bitmapStart | The address of the sector where the bitmap of the first band (that is, band 0) starts. This is usually the sector right after the superblock. For any other band, the bitmap must start in the first sector of the band. The size of the bitmap in each band is related to the logSectorsPerBand field. |
uint64_t rootInode | The inode number (that is, the address of the first sector) of the root directory. This is usually the sector right after the bitmap for band 0. |
uint64_t badInode | The inode number (that is, the address of the first sector) of a pseudo-file to track bad sectors. This pseudo-file should be generated and managed by a file system checkup program, and should be made up of any sectors that the program detected as bad. This ensures that a driver can not allocate them. If the volume has no bad sectors, badInode must be zero. |
uint8_t reserved2[360] | Reserved for future use. These bytes pad the size of the superblock structure to 512 bytes and must be included in checksum calculation. |
The bitmap
The bitmap is a non-contiguous data structure, made up of sectors that, as a whole, form an array of bits, each of them indicating the allocated/unallocated state of each sector of a volume. The bitmap is not contiguous because its sectors are subdivided into bands, instead of being stored in a single chunk in a fixed location.
The total number of sectors in a volume is specified by the sectorCount field of the superblock. Thus, the bitmap as a whole must contain sectorCount bits, one for each sector. The number of sectors required to store the bitmap (that is, the total bitmap size) is given by ceil(sectorCount / (512 * 8)), where ceil means round up. Any bits after the first sectorCount are unspecified. Each band must store a portion of the bitmap, according to the band size in sectors, that is the size of each bitmap portion must be sectorsPerBand / (512 * 8) sectors, where sectorsPerBand can be easily computed from the superblock. The size of each bitmap portion will result an integral number of sectors due to the constrains specified for logSectorsPerBand.
A bit of the bitmap must be set to '1' if its corresponding sector is used/allocated, whereas it must be set to '0' if its corresponding sector is free/unallocated. Sector 0 is identified by bit 0 (the LSB) of the first byte of the bitmap, sector 1 by bit 1 of the first byte, sector 7 by bit 7 (the MSB) of the first byte, sector 8 by bit 0 of the second byte, and so on.
The sectors occupied by the superblock, the superblock backup, the bitmap itself and any reserved sectors containing boot loader code are not free for data storage, thus must be marked as allocated in the bitmap.
The following code snippet shows how to locate a bit for the sector specified by sector.
/* The following input values and precalculated values are assumed: uin64_t sector = the sector to locate the bitmap entry for Superblock sb = a structure containing the superblock uint64_t sectorsPerBand = 1 << sb.logSectorsPerBand const size_t logSectorSize = 9; const size_t sectorSize = 512; */ uint64_t band = sector >> sb.logSectorsPerBand; uint64_t sectorInBand = sector & (sectorsPerBand - 1); uint64_t bitmapSector = (sectorInBand >> (3 + logSectorSize)) + (band << sb.logSectorsPerBand); if (band == 0) bitmapSector += sb.bitmapStart; unsigned bitOfSector = sectorInBand & (sectorSize * 8 - 1);
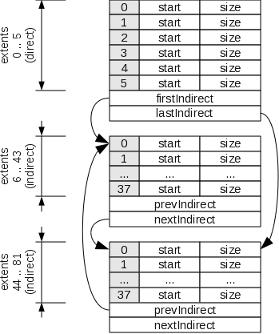
Figure 2: File Allocation in LEAN.
The data area and file allocation
The data area is made up of any sector not used by the bitmap, the superblock, the superblock backup and sectors reserved for boot code. It is in general not contiguous due to the band-based layout of the bitmap. It stores actual file system contents: files, directories and their related book keeping (that is the list of their allocated sectors).
Besides being unused, each sector in the data area can be either a data sector or an indirect sector. The former contains actual data, the latter contains book keeping. Data sectors are grouped together to form extents when they are contiguous. An extent is specified by a starting address and a size in sectors.
Each file is stored in one or more extents, thus file allocation can be described as an array of extent specifications. The first sector of a file stores the inode structure of the file. Actual file data begins after the inode structure, and after the optional extra space after the inode structure reserved for inline extended attributes. This introduces an offset when converting between file data position and data sectors. The inode structure and indirect sectors are used to know what extents belong to a file. This is done in two ways: direct addressing and indirect addressing.
Direct addressing
To speed up file access on small files, a limited number of extent specifications is stored in the inode structure itself. A driver must use this information to directly access any of the first extents of the file in constant time. The constant extentsPerInode, currently defined to 6, specifies how many extent specifications are saved in the inode structure.
Indirect addressing
If a file needs more than extentsPerInode extents, indirect addressing is used for subsequent extents. An indirect sector is a sector storing an array of extentsPerIndirect = 38 extent specifications instead of file data. Indirect sectors are linked together to form a doubly-linked list in order to support arbitrary file lengths.
The following is the layout of an indirect sector. Please note that, being an extent specification a 12-byte quantity (64-bit address + 32-bit size), extent starting sectors and sizes have been split in two distinct arrays to keep proper alignment.
uint32_t checksum | The checksum value for the indirect sector. All bytes in the sector do count for checksum calculation. |
uint32_t magic | This must be equal to 0x58444E49 (the 'INDX' characters in ASCII). |
uint64_t sectorCount | The total number of sectors addressable using this indirect sector. A driver should use this information to quickly traverse the list of indirect sectors to find the desired data sector. It must be equal to the sum of the used extentSizes (see below). |
uint64_t inode | The inode number of the file this indirect sector belongs to. This is provided for robustness. |
uint64_t thisSector | The address of the sector storing this indirect sector. This is provided for robustness. |
uint64_t prevIndirect | The address of the previous indirect sector. If there is no previous indirect sector, this field must be zero. A driver may use this value to traverse the list of indirect sectors in reverse order. |
uint64_t nextIndirect | The address of the next indirect sector. If there is no next indirect sector, this field must be zero. This is the primary means for a driver to traverse the list of indirect sectors to seek into a file. |
uint8_t extentCount | The number of valid extent specifications stored in the indirect sector, that is the count of the first elements in the extentStarts and extentSizes arrays that refer to actual file extents. If the indirect sector is not the last indirect sector of a file, all extent specifications must be in use, that is extentCount must be equal to extentsPerIndirect. |
uint8_t reserved1[3] | Padding, reserved for future use. |
uint32_t reserved2 | Padding, reserved for future use. |
uint64_t extentStarts[extentsPerIndirect] | The array of starting sector addresses of the extent specifications. |
uint32_t extentSizes[extentsPerIndirect] | The array of extent sizes of the extent specifications. Each element represents the size in sectors of the corresponding extent whose first sector is specified in extentStarts. |
Rationale
The extent-based approach allows efficient and simple access to the file system. It is efficient because, once the driver knows an extent specification, it can access any sector of that extent in constant time. It is also simple because, for each extent, only an offset must be added to its starting sector to find any other sector.
This works best if the file is not badly fragmented, that is unless the file is made up of several extents. Being the first extentsPerInode extent specifications saved in the inode structure, it is expected that most small files would need no indirect sectors, thus any sector can be accessed in constant time with no additional reads. Large files can benefit from this too, if they are mostly contiguous, although this is not as likely.
Indirect sectors store a much greater amount of extent specifications than the inode structure, thus it is expected that with a few indirect sectors a file is completely specified. For example using just 5 indirect sectors it is possible to specify a file made up of 196 fragments. They may be buffered for faster operation. The number of indirect sectors, if any are present, is determined only by the count of fragments, not by the file size (at least not directly).
This approach has been chosen in order to advantage random access on small files (e.g. configuration files), but sequential access for bigger files (e.g. multimedia files), as well as keeping the file system implementation as simple as possible.
Allocation strategies
In order to use the file system as efficiently as possible, drivers may implement allocation strategies when creating or extending files. This specification does not define or mandate such allocation strategies, but a few suggestions are presented.
When extending a file, a driver should try to grow its last extent. The last extent of a file can be easily found using the extentCount and/or lastIndirect fields of the inode structure. The following algorithm for adding one sector to a file may be used:
if the sector right after the end of the last extent is free
{
grow the last extent increasing its size by 1;
}
else
{
find a free sector as close as possible to the last extent;
if a new indirect sector is needed
{
write the indirect sector in that free sector;
find a free sector as close as possible to the indirect sector just written;
}
create a new extent starting at that free sector and with size 1;
}
Drivers may use a modified version of the algorithm above, by trying to allocate and add more than one sector at a time. This is expected to reduce fragmentation and improve locality, especially on slowly-growing files such as directories.
To improve locality in space between directories and their files, and to help reduce fragmentation, a driver may use the following algorithm when creating a new file. It assumes that most files will have a single hard link, thus a single parent directory:
locate the band where the parent directory of the new file ends;
if the new file is not a directory
{
find a free sector as close as possible to the end of the parent directory;
}
else
{
generate a band number different from the one of the parent directory;
find a free sector in that band;
}
create the new file in that sector and store there its inode structure;
To help implementing these algorithms, a driver may provide a parametric procedure for searching for free sectors, specifying a suggested sector where to start to search from and a suggested sector count.
The inode structure
All fundamental metadata of a file are stored in a structure called inode structure. Such file metadata include file size, attributes and time stamps, as well as the means to access directly- and indirectly-addressable extents of a file.
The inode structure must be stored at offset zero of the first data sector of a file. The address of that first data sector must be used as inode number, that is a serial number to uniquely identify the file in a volume. It is not supposed to uniquely identify the file on the whole system: the operating system or a driver may use the inode number together with some way to identify the volume (for example, its UUID or an opaque identifier) to uniquely identify the file system-wise.
Putting the inode structure in a file data sector allows to avoid a separate inode table, allowing an arbitrary number of files per volume and simplifying inode management, at the price of some disk space (especially for very small files that would otherwise fit in a single sector or zero-length files) and possible performance degradation when doing a detailed directory listing including file metadata.
The inode structure is 176 bytes long, and its format is defined in the following table. Drivers may opt to keep the whole structure in memory for open files, or use a larger inode cache, or, if memory is a scarce resource, keep only a minimal amount of metadata and read the inode structure from disk whenever needed. Actual file data start right after the inode structure or, if the iaInlineExtAttr attribute is set, at the beginning of the subsequent data sector (perhaps in the same extent).
| Field | Description |
|---|---|
uint32_t checksum | The checksum value for the inode structure. Any inline extended attributes following the inode structure are not part of the inode structure itself, thus must not be included in checksum calculation. |
uint32_t magic | This must be equal to 0x45444F4E (the 'NODE' characters in ASCII). |
uint8_t extentCount | The number of valid extent specifications stored in the inode structure, that is the count of the first elements in the extentStarts and extentSizes arrays that refer to actual file extents, from 1 (the first extent contains the inode structure itself) to extentsPerInode = 6. Directly-addressable extents must be used from the first to the last before using indirect sectors. If extentCount < extentsPerInode, unused extent specification are undefined. |
uint8_t reserved[3] | Padding, reserved for future use. |
uint32_t indirectCount | The number of indirect sectors owned by the file. |
uint32_t linkCount | If this file is not a fork, this field must be equal to the number of hard links (the count of directory entries) referring to this file. If this file is a fork, this field must be equal to the number of non-fork files referring to this fork. Drivers may implement fork sharing and copy-on-write. In any case, for non-deleted files this field must be at least 1. |
uint32_t uid | The numeric identifier of the user that owns the file. Interpretation of this field is operating system dependent. A monouser driver must use zero. |
uint32_t gid | The numeric identifier of the group that owns of the file. Interpretation of this field is operating system dependent. A monouser driver must use zero. |
uint32_t attributes | The attributes mask for the file, see enum InodeAttributes. It includes POSIX permissions, behavior flags and the file type specification. Interpretation of permissions is operating system dependent. A monouser driver must use the owner user permission bits only (ia?USR). Note that the "file type" values are mutually exclusive enumerated values, they are not single bits that can be combined. The iaFmtMask mask can be used to retrieve the file type. |
uint64_t fileSize | The size in bytes of the file data, thus excluding the size of the inode structure, the optional extra space for inline extended attributes, and indirect sectors. |
uint64_t sectorCount | The number of data sectors (thus excluding indirect sectors, and including the first sector with the inode structure) allocated for the file. A driver may preallocate more sectors than required for a specified fileSize to implement strategies to reduce fragmentation. |
int64_t accessTime | Last access time stamp. This field is computed as the signed number of microseconds since 1970-01-01 00:00:00.000000 UTC, not including leap seconds. Drivers may choose to not update this field if performance is a costraint or the disk has limited write capabilities (e.g. flash memories). A mount-time flag or an open-time flag may be implemented to disable last access time stamps, and the implementation may want this to be the default. Initially it must have the same value as creationTime. If the operating system semantics allows it, drivers may delay update of this time stamp instead of updating it at every access. |
int64_t statusChangeTime | Status modification time stamp. This field is computed as the signed number of microseconds since 1970-01-01 00:00:00.000000 UTC, not including leap seconds. Initially it must have the same value as creationTime. If the operating system semantics allows it, drivers may delay update of this time stamp instead of updating it at every modification to the inode structure. |
int64_t modificationTime | Last data modification time stamp. This field is computed as the signed number of microseconds since 1970-01-01 00:00:00.000000 UTC, not including leap seconds. Initially it must have the same value as creationTime. If the operating system semantics allows it, drivers may delay update of this time stamp instead of updating it at every write to the file. |
int64_t creationTime | File creation time stamp. This field is computed as the signed number of microseconds since 1970-01-01 00:00:00.000000 UTC, not including leap seconds. Depending on the operating system semantics, this field may be greater than the other time stamps if this file is created as a copy of an existing file. |
uint64_t firstIndirect | The address of the first indirect sector of the file. If the file has no indirect sectors the value of this field must be zero. |
uint64_t lastIndirect | The address of the last indirect sector of the file. If the file has no indirect sectors the value of this field must be zero. |
uint64_t fork | If this file is not a fork, this field is the address of the first sector of the optional fork associated with this file, or zero if this file has not a fork. If this file is a fork, this field must be zero. |
uint64_t extentStarts[extentsPerInode] | The array of starting sector addresses of the extent specifications. The count of valid extent specifications, starting from index 0, is determined by the extentCount field. Any unused extent specification is unspecified. Note that the first element of this array is also -by definition- the address of the sector containing this inode structure. |
uint32_t extentSizes[extentsPerInode] | The array of extent sizes of the extent specifications. Each element represents the size in sectors of the corresponding extent whose first sector is specified in extentStarts. |
| Symbolic name | Value | Description |
|---|---|---|
| iaRUSR | 1 << 8 | POSIX permissions: owner user can read (same as S_IRUSR) |
| iaWUSR | 1 << 7 | POSIX permissions: owner user can write (same as S_IWUSR) |
| iaXUSR | 1 << 6 | POSIX permissions: owner user can execute/search in directory (same as S_IXUSR) |
| iaRGRP | 1 << 5 | POSIX permissions: owner group can read (same as S_IRGRP) |
| iaWGRP | 1 << 4 | POSIX permissions: owner group can write (same as S_IWGRP) |
| iaXGRP | 1 << 3 | POSIX permissions: owner group can execute/search in directory (same as S_IXGRP) |
| iaROTH | 1 << 2 | POSIX permissions: others can read (same as S_IROTH) |
| iaWOTH | 1 << 1 | POSIX permissions: others can write (same as S_IWOTH) |
| iaXOTH | 1 << 0 | POSIX permissions: others can execute/search in directory (same as S_IXOTH) |
| iaSUID | 1 << 11 | POSIX permissions: execute as user ID (same as S_ISUID) |
| iaSGID | 1 << 10 | POSIX permissions: execute as group ID (same as S_ISGID) |
| iaSVTX | 1 << 9 | POSIX permissions: restrict rename/delete to owner (same as S_ISVTX) |
| iaHidden | 1 << 12 | Do not show in default directory listings |
| iaSystem | 1 << 13 | Warn that this is a system file |
| iaArchive | 1 << 14 | File changed since last backup (must be set on any write) |
| iaSync | 1 << 15 | Writes must be committed immediatly (besides open- or mount-time flags) |
| iaNoAccessTime | 1 << 16 | Do not update last access time (besides open- or mount-time flags) |
| iaImmutable | 1 << 17 | Do not move file sectors (e.g. for defraggers) |
| iaPrealloc | 1 << 18 | Keep any preallocated sectors beyond fileSize when the file is closed (recommended for directories) |
| iaInlineExtAttr | 1 << 19 | The remaining bytes after the inode structure in the first sector are reserved for inline extended attributes |
| iaFmtMask | 7 << 29 | Bit mask to extract the file type |
| iaFmtRegular | 1 << 29 | File type: regular file (see enum FileType) |
| iaFmtDirectory | 2 << 29 | File type: directory (see enum FileType) |
| iaFmtSymlink | 3 << 29 | File type: symbolic link (see enum FileType) |
| iaFmtFork | 4 << 29 | File type: fork (see Extended attributes) |

Figure 3: Directory format in LEAN.
Directories
A directory is a file containing an unordered list of directory entries. Each directory entry is a structure which binds a file name with an inode structure, thus each directory entry is a hard link to a file. Directory entries do not store file metadata, except what specified below.
A directory entry is a variable length structure, containing a fixed 12-byte header and a variable length part containing the file name. Every directory entry must be aligned to a 16-byte boundary, thus the size of the whole structure must be a multiple of 16 bytes. This helps to reuse space from deleted directory entries. A single directory entry may span across different sectors.
File name storage must be case sensitive in order to simplify name comparison, avoiding case folding to upper or lower case, that is not trivial in Unicode and may depend on the locale. This means that filename.ext and FileName.Ext may reside in the same directory and refer to two different files. For this reason, drivers need not to be Unicode-aware, and file name matching can be as simple as using memcmp. Drivers may implement case insensitive file name matching in an unspecified way, for example using first-match or best-match policies. Every file name in a directory must be unique. In environments lacking support for long file names, or requiring short file name aliases, a driver may fabricate short file names on the fly, that is, without having them physically stored in the directory. The algorithm used to fabricate short file names is unspecified, but a proposed procedure is shown below.
A single file, identified by its inode number, may be represented by one or more directory entries, residing in any directory: these are the hard links to the file. A file must have at least one hard link. When a file has no more hard links, it must be deleted from a volume. Forks are an exception because, by definition, they are associated with another file and have no own directory entries, and their lifetime is specified by the files they are associated with. Directories must have exactly one parent, that is one hard link besides the ones from the special "." (dot) and ".." (dot-dot) entries, in order to prevent cycles.
This is the format of a directory entry:
| Field | Description |
|---|---|
uint64_t inode | The inode number of the file linked by this directory entry, that is the address of the first sector of the file. Drivers must use it to locate the inode structure to do any subsequent processing on the file. |
uint8_t type | This is a shortcut to the file type, see enum FileType. A driver must keep it consistent with the file type bits in the attributes of the inode structure. |
uint8_t recLen | This is the total size (thus including the fixed length header) of the directory entry, in 16-byte units. It must be at least 1. This field must be valid even for deleted or empty directory entries, as it must be used as a link to the next directory entry. |
uint16_t nameLen | The length in bytes of the file name stored in the name field. It must be greater than zero. |
char name[] | The file name. This string must not be null-terminated and must be encoded in Unicode UTF-8. Its length must be be determined solely by the nameLen field, and padding bytes optionally present after the nameLen bytes are undefined. All Unicode code points are allowed. |
The following table shows the possible values for the type field of a directory entry. A value of zero must indicate that the directory entry is empty (available, or deleted). A file may be undeleted by setting type back to the corresponding value in the inode structure, until its sectors are physically overwritten (all magic and checksum fields should be checked for robustness in this case). Note that these values are mutually exclusive enumerated values, they are not single bits that can be combined, and that -by definition- there is no type for forks.
| Symbolic name | Value | Description |
|---|---|---|
| ftNone | 0 | No file type, the directory entry is empty |
| ftRegular | iaFmtRegular >> 29 = 1 | Regular file |
| ftDirectory | iaFmtDirectory >> 29 = 2 | Directory |
| ftSymlink | iaFmtSymlink >> 29 = 3 | Symbolic link |
"." and ".." entries
The two special entries "." (dot) and ".." (dot-dot) must be the first and the second entry of every directory, respectively. The former must be a hard link to the directory itself, the latter must be a hard link to the parent directory. In the root directory, which has no parent, ".." must be a hard link to itself, too.
A driver may use fictitious "." and ".." entries ignoring the actual entries in the directory, for example to assign ".." to the parent directory of a mount point. If showing "." and ".." to the user is a concern, a driver may choose to make them hidden entries, for example those of the root directory.
Looking up a directory
This algorithm must be used to search for an entry in a directory, using appropriate file name matching criteria:
while not EOF
{
read a 12-byte directory header;
if (DirEntry.type != ftNone)
{
read the file name and compare it against the required file name;
if the required entry is found return this directory entry;
}
advance using the information provided in recLen;
}
return "file not found";
Deleting an entry
To delete a hard link to a file, a driver must set the type field of the directory entry to zero (that is ftNone) and decrease the linkCount field of its inode structure. The space occupied by the deleted directory entry (recLen*16 bytes) is made available for reuse (see the 4th entry in figure 3). If some degree of security is needed, a driver may zero all bytes of a directory entry, except recLen.
If the linkCount of the inode structure of the file reaches zero, the sectors of the file (both data and indirect) must be deleted, and, if the file has a fork, its linkCount must be decremented, deleting the fork (both data and indirect sectors) if it reaches zero. To do this, drivers must set the corresponding bits in the bitmap to '0'. This is efficient and allows to recover data, until physically overwritten. If some degree of security is needed, a driver may also zero or fill with garbage the actual content of the deleted sectors.
Creating an entry
This procedure must be used to create a new hard link to a file.
Scan the directory for one or more contiguous available directory entries, enough to store the new directory entry. This is because available entries are not coalesced together. The required size of the directory entry, in 16-byte units, must be computed as recLen = ceil((12 + nameLen) / 16). Available directory entries must be identified for having type == ftNone (see above).
If enough space to store the new directory entry is found, the new directory entry should be stored in that place, otherwise the new directory entry must be appended to the directory, thus extending it. If the new directory entry is shorter than the free space found, a driver must fabricate and append a new directory entry header (with type equal to ftNone) to keep the link with the next directory entry consistent (see the 7th entry in figure 3).
Fabricating a short file name
In environments lacking support for long file names, or requiring short file name aliases, a driver may fabricate short file names. Fabricated short file names are not supposed to be stored on the file system as new hard links, but rather generated on the fly to the user when they are needed. How to fabricate short file names in such cases is unspecified. The following is an algorithm that drivers may use if appropriate:
- find the last dot, if any, in the file name, and assume it to be the separator between the name prefix and the name extension;
- remove any invalid character from the original file name;
- convert the resulting name to the required character set, if any;
- truncate the name prefix and the name extension to the required lengths;
- take the offset where the directory entry starts inside the directory containing it, and divide that offset by 16 (all directory entries are multiple of 16 bytes);
- append this number to the name prefix, to make sure it is unique in the directory (hex numbers may be used to shorten the numeric tail), truncating the name prefix further, if required, to fit a short file name.
Symbolic links
A symbolic link (symlink, soft link) is a special file storing the pathname of another file. Its file type must be ftSymlink.
The string representing the pathname must be encoded in Unicode UTF-8 and must not be null-terminated. The length of this string must be equal to the file size of the symbolic link.
The represented pathname may be either absolute or relative. A driver or other appropriate parts of an implementation should provide the means to follow the symbolic link. In a system where pathnames may include a drive or device specification, the pathname stored by the symbolic link may contain a drive or device specification too. The way the implementation behaves in the event the drive or device referred by the symbolic link changes (for example a removable or network drive, or when the volume is used in a system not supporting drive or device specifications) is implementation specific.
The meaning of attributes for symbolic links is unspecified. A driver may apply their regular meaning to the symbolic link itself (for example, a hidden symbolic link may be not showed in a directory listing, whether the target is hidden or not, or the permissions of a symbolic link may refer to what can be done with the target when accessed via the symbolic link), or may use any conventions normally used by the system for symbolic links.
Extented attributes
Extended attributes are optional metadata, not directly interpreted by the file system, that can be attached to a file system object. They are basically name-value pairs, each of it called an extended attribute record.
The LEAN file system allows to store extended attributes inline, right after the inode structure of each file, before file data, or in a separate fork of the file. In LEAN a fork is just a file containing extended attribute records, associated with another file system object, and with no directory entries. Inline extended attributes allow to store only a limited amount of metadata, but offer better performance. A fork allows to store much more metadata (theoretically forks can be as big as regular files), but requires additional disk access.
Any kind of name-value pairs can be stored as extended attributes. The freedesktop.org project provides recommendations for a portable set of extended attributes.
Whether an extended attribute record is stored in the extra space after the inode structure or in a fork, it is a variable-length structure with a 32-bit header, with size constrained to multiples of 4 bytes, and the following format:
| Field | Description |
|---|---|
uint32_t header | The fixed header of the record. It must be interpreted as 0xNNVVVVVV, where the highest 8 bits (31..24), NN, represent the lenght in bytes of the attribute name, and the lowest 24 bits (23..0), VVVVVV, represent the size in bytes of the attribute value. If NN is 0, this is an empty record used for padding (perhaps a deleted record), and VVVVVV indicates the size of the whole record, excluding the 32-bit header. |
char name[] | The attribute name, that is a UTF-8, case-sensitive string that must uniquely identify what this attribute means, formatted as a dot-separated name-spaced name. The null character (U+0000) is not allowed for compatibility with existing extended attribute APIs. |
uint8_t value[] | The attribute value. It may have any format that makes sense to the application that manages the attribute. If it is a text, it should be encoded in UTF-8. If NN + VVVVVV is not a multiple of 4, undefined padding bytes must be added after the value to reach a multiple of 4 bytes. |
If the file has the iaInlineExtAttr attribute set, the extra space after the inode structure must be completely filled with contiguous extended attribute records, perhaps padding ones. This means that, at the very least, a single record whose header has NN = 0 and VVVVVV = sectorSize - sizeof(Inode) - sizeof(uint32_t) must be present, meaning that the whole extra space is unused. Drivers should prefer inlining extended attributes that are prioritary, frequently used and small.
If the fork field of the inode structure is nonzero, that inode has an associated fork whose first sector is specified by fork. That fork is a file system object, thus it must have its own inode structure. That inode structure must have the iaInlineExtAttr attribute not set, file type iaFmtFork and the fork field must be set to zero. The fileSize field of the inode structure of the fork must indicate how many bytes of extended attribute records are present in the fork. The fork must be made of a contiguous sequence of extended attribute records, perhaps padding ones.
Drivers are not required to understand extended attributes, and must not rely on them being present. Fundamental metadata must be stored in the appropriate fields of the inode structure. A driver not supporting extended attributes must leave them untouched, but must be able to delete them when the inode they are associated with is deleted. This means, at least, marking any fork sectors (data and indirect) as free in the bitmap. Drivers should not make any modification to the content of extended attributes they do not know about.
If the size of all extended attributes of a file is reasonably small, drivers may opt to cache all of them in memory, and write them back to disk as a whole. Drivers may rearrange the sequence of extended attribute records, provided that the constrains above are enforced. If using a fork, drivers may want to store all extended attributes in a single extent whenever possible. Drivers should try to allocate space for the fork as close as possible to the inode structure of the file system object the fork is associated with.
When enumerating extended attributes, drivers should start from the inline ones, if any, then continue with those in the fork, if any. When saving extended attributes, drivers should provide to applications a way (such as a "priority" flag) to specify whether the attribute should be saved inline if possible, or in a fork. Drivers may implement policies to restrict editing of certain extended attributes to system services only (for example, attribute names starting with "system."). An application of this could be using one extended attribute record to implement Access Control Lists: in this case, drivers may want to place that record inline and forbid their editing to unprivileged users.